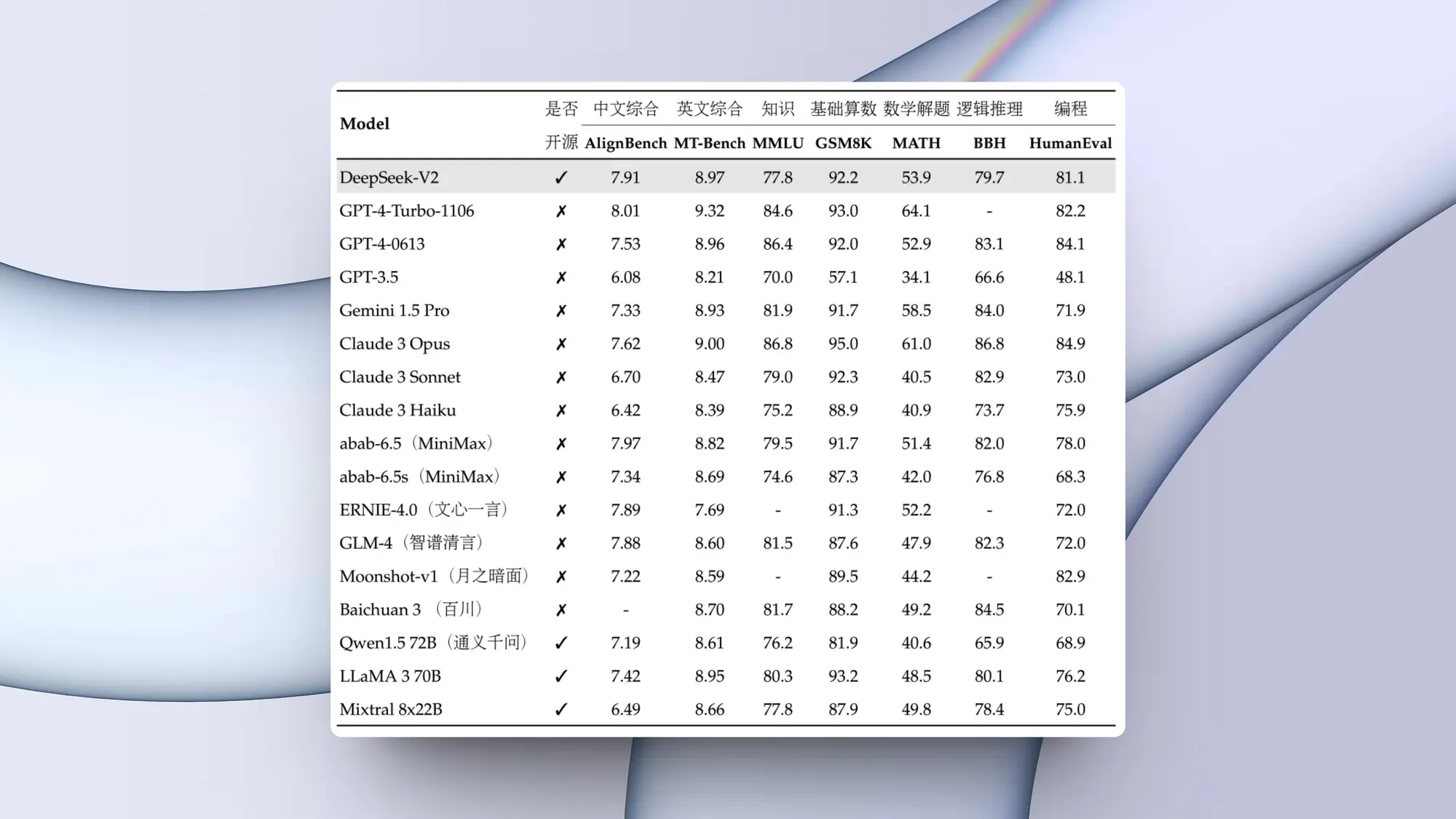
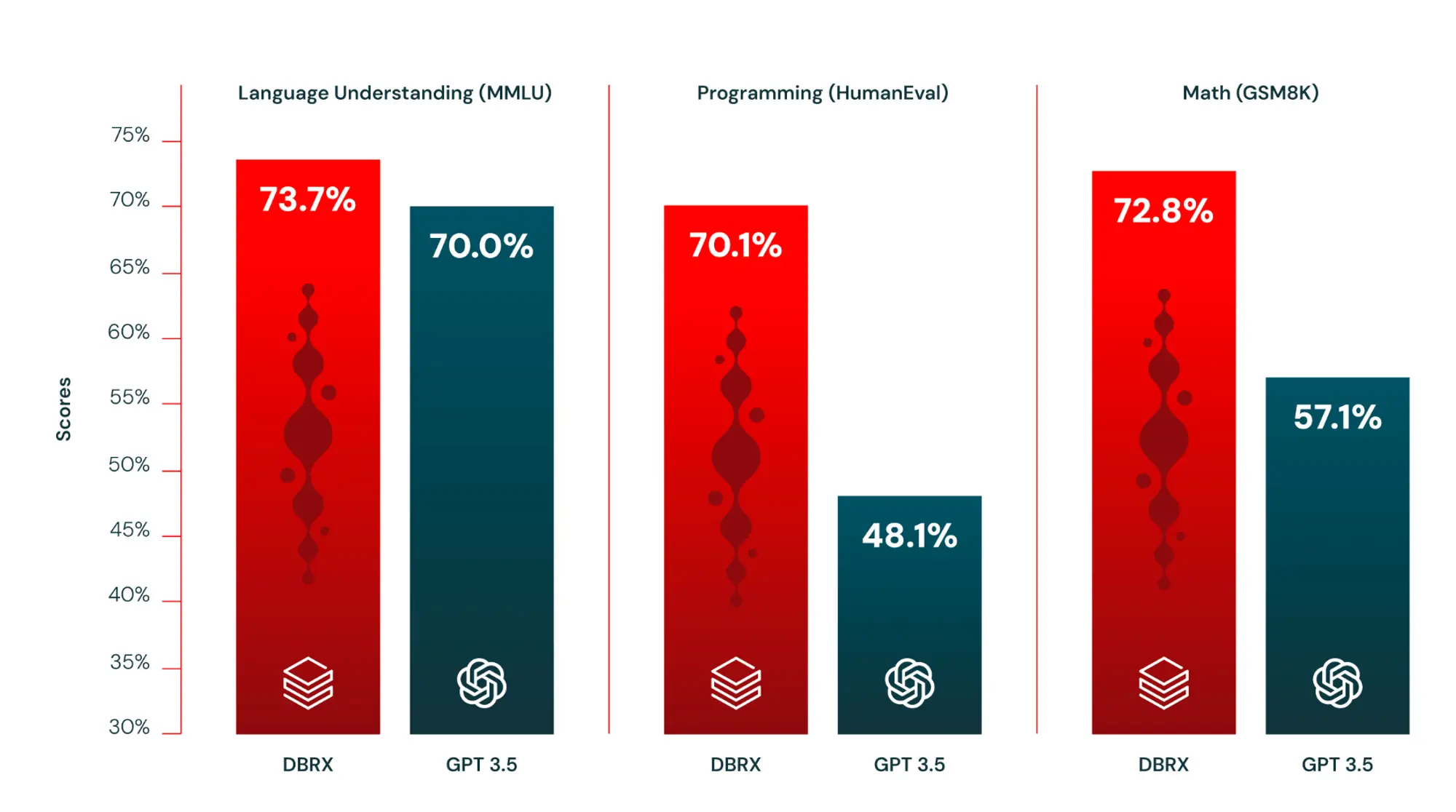
将网络信息灌输到大语言模型(llm)中是实现信息实体化的关键步骤,但这一过程充满挑战。最直接的方法是直接抓取内容并提取其 html 数据。然而,抓取操作往往复杂且容易受到封锁,且原始 html 往往包含大量无用的元素,如多余的标记和脚本代码。reader api 解决了这些问题,它能从网址提取出核心内容,并将其转化为干净、易于大语言模型处理的文本,确保为你的 ai 智能体及 rag 系统提供高品质的数据输入。
原创文章,作者:校长,如若转载,请注明出处:https://www.yundongfang.com/yun295783.html
 微信扫一扫不于多少!
微信扫一扫不于多少!  支付宝扫一扫礼轻情意重
支付宝扫一扫礼轻情意重