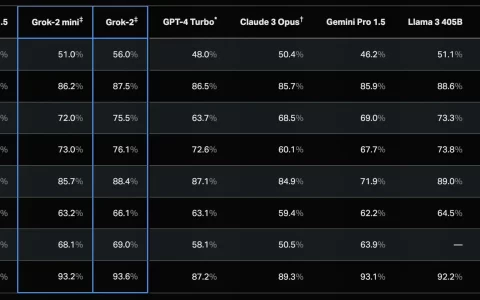
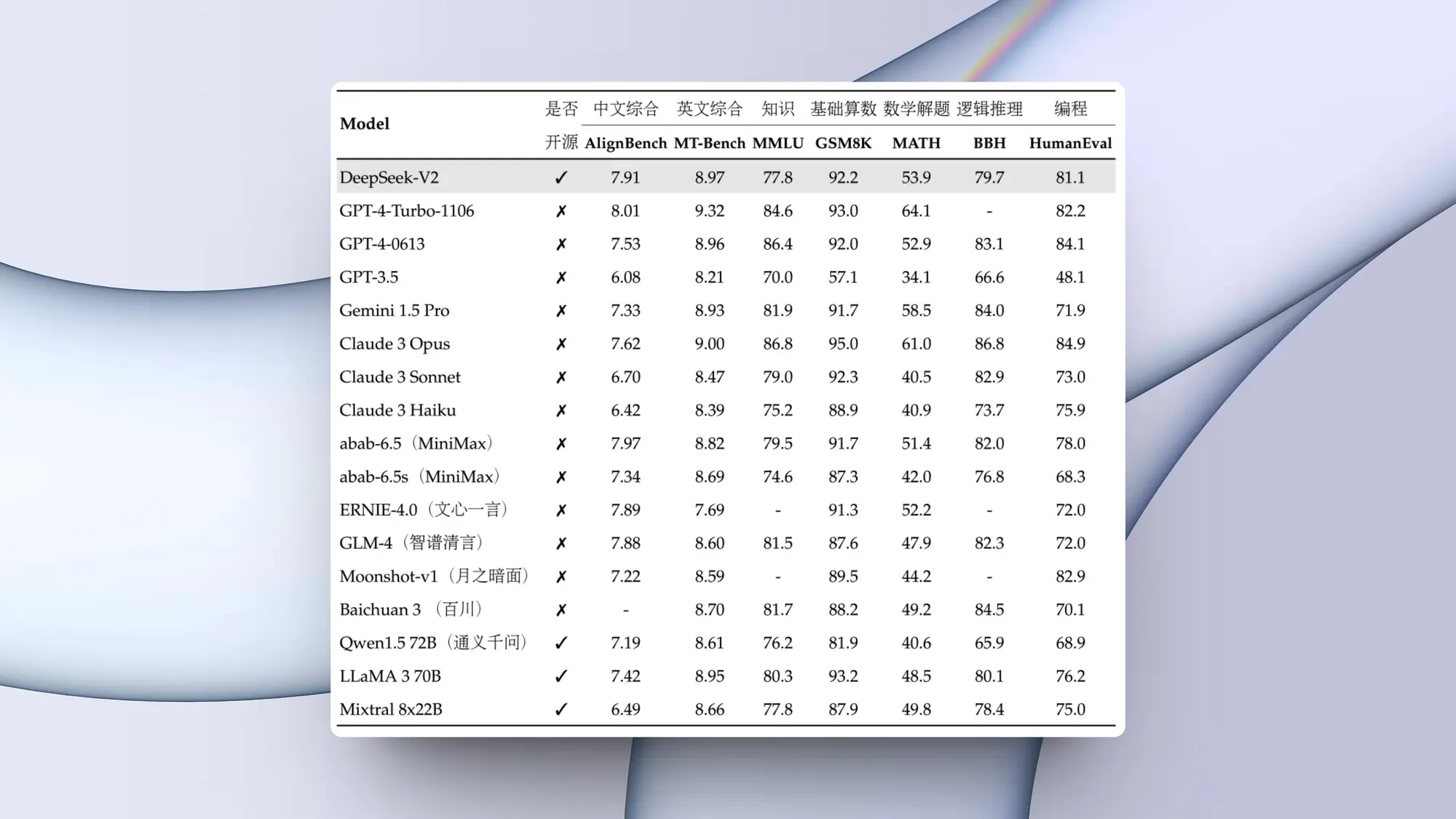
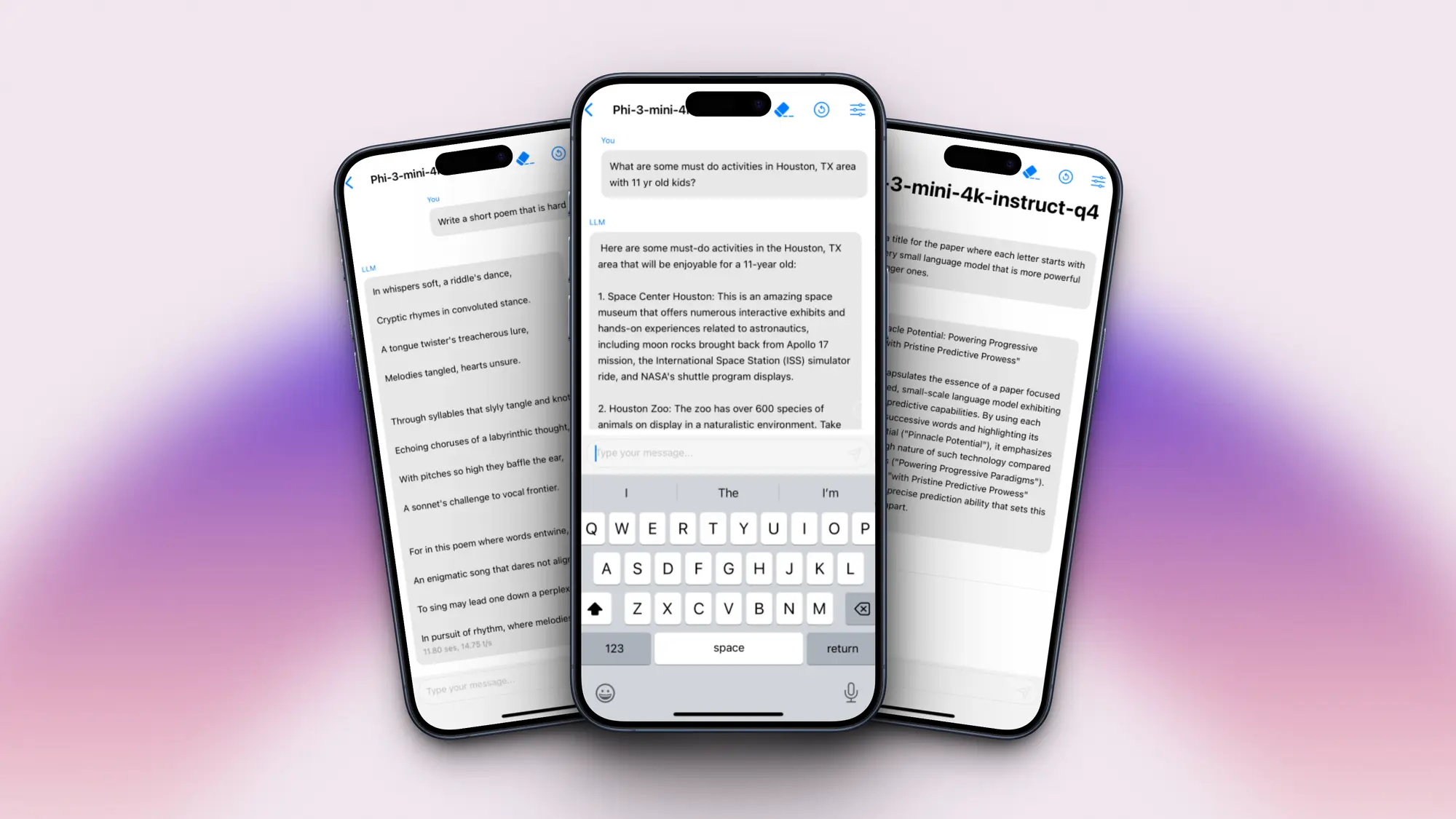
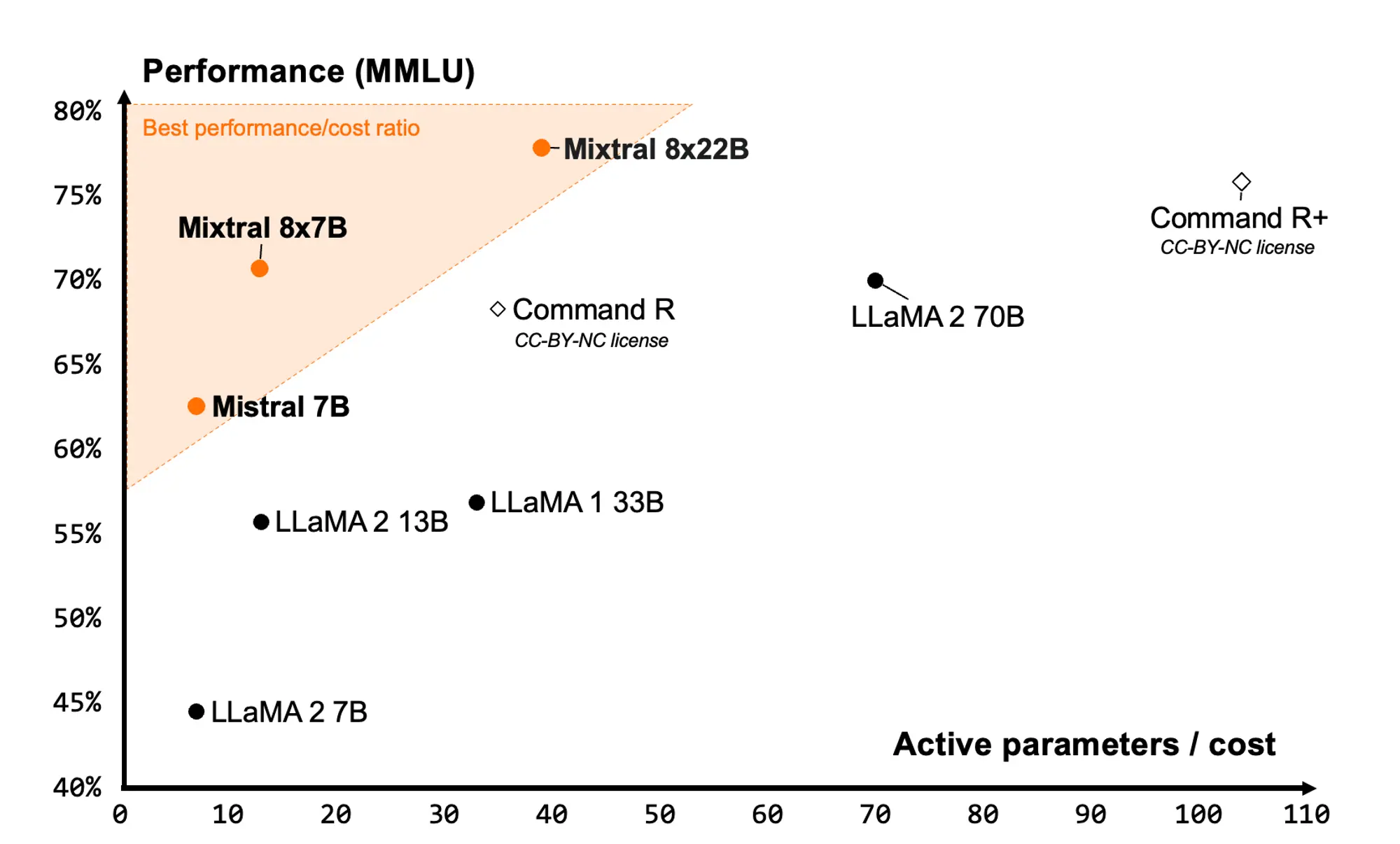
openai 首席技术官 (cto) mira murati 在接受《华尔街日报》采访时,对 openai 的文本转视频模型 sora 的预期发布和开发挑战提供了见解。sora 文本到视频 ai 生成器预计将在今年内由 openai 发布,甚至可能在未来几个月内发布,这是一个非常令人兴奋的消息。观看下面对 murati 的 10 分钟快速采访,更深入地了解我们在不久的将来对 sora 和 openai 的期望。
openai sora 发布日期
openai 首席技术官 mira murati 在接受《华尔街日报》采访时暗示了 sora ai 的发布。人们的期待不仅在于技术本身,还在于它在各种应用中的潜力。openai 正在正面解决的主要障碍之一是这项复杂技术的成本。目标是使 sora ai 尽可能实惠,理想情况下与 openai 的图像创建者 dalle 3 相关的成本相当。虽然这是一个具有挑战性的雄心壮志,但它强调了该组织致力于让更广泛的受众能够获得尖端技术。
murati 解释说,sora ai 的制作考虑到了您的需求,确保界面尽可能直观。如果您曾经与 chatgpt 互动过,您会发现 sora ai 的界面非常熟悉,可以进行流畅直接的交流。此外,开发人员将能够通过 api 将 sora ai 集成到他们自己的应用程序中,从而为将这种先进的文本到视频模型整合到各种软件和服务中开辟了一个充满可能性的世界。
openai 首席技术官 mira murati 接受《华尔街日报》采访
ai视频生成器仍处于早期开发阶段
然而,重要的是要认识到 sora ai 仍在进行中。与任何新兴技术一样,有一些问题需要解决。该模型的当前版本可能并不总是生成与输入提示完全匹配的视频,并且您可能会偶尔遇到故障。这些不是不可逾越的障碍,而是正在进行的改进过程中的步骤。openai 正在积极致力于解决这些问题,重点是提高模型的精度和整体功能。
openai解释说,它正在教人工智能理解和模拟运动中的物理世界,目的是训练模型,帮助人们解决需要现实世界交互的问题。sora,它的文本到视频模型可以生成长达一分钟的视频,同时保持视觉质量并遵守用户的提示。
红队队员可以使用 sora 来评估关键区域的危害或风险。我们还向一些视觉艺术家、设计师和电影制作人授予访问权限,以获得有关如何推进模型以对创意专业人士最有帮助的反馈。文本到视频的 ai 能够生成具有多个角色、特定类型的运动以及主题和背景的准确细节的复杂场景。该模型不仅了解用户在提示中要求的内容,还了解这些东西在物理世界中的存在方式。
sora ai 模型对语言有深刻的理解,使其能够准确解释提示并生成表达生动情感的引人注目的角色。sora 还可以在单个生成的视频中创建多个镜头,以准确保留角色和视觉风格。
当前限制
“目前的模式有弱点。它可能难以准确模拟复杂场景的物理特性,并且可能无法理解因果关系的具体实例。例如,一个人可能会咬一口饼干,但之后,饼干可能没有咬痕。该模型还可能混淆提示的空间细节,例如,左右混淆,并且可能难以精确描述随时间发生的事件,例如遵循特定的相机轨迹。
因此,请密切关注 sora ai 的地平线。将文本转换为视频的潜力即将成为现实,它有望为创造力和交流开辟新的途径。无论您是内容创作者、教育工作者,还是只是喜欢探索最新技术的人,sora ai 都将提供一种令人兴奋的新方式来参与数字世界。预计 sora 将很快出现在 openai 的所有产品和 ai 服务中。我们将一如既往地让您了解可能提供的任何发展和新闻。
原创文章,作者:校长,如若转载,请注明出处:https://www.yundongfang.com/yun289212.html
 微信扫一扫不于多少!
微信扫一扫不于多少!  支付宝扫一扫礼轻情意重
支付宝扫一扫礼轻情意重