如果您有兴趣了解有关如何对ai大型模型或llm进行基准测试的更多信息,那么一种新的基准测试工具agent bench已成为游戏规则的改变者。这个创新工具经过精心设计,将大型语言模型列为代理,对其性能进行全面评估。该工具的首次亮相已经在ai社区掀起了波澜,揭示了chatgpt-4目前作为性能最佳的大型语言模型而位居榜首。
agent bench不仅仅是一种工具,而是ai行业的一场革命。它是一个开源平台,可以在桌面上轻松下载和使用,使广泛的用户可以访问它。该工具的多功能性体现在它能够在八个不同的环境中评估语言模型。这些包括操作系统、数据库、知识图谱、数字纸牌游戏、横向思维拼图、家务、网上购物和网页浏览。
打开法学硕士排行榜
开放llm排行榜是一个重要的项目,旨在持续监控,排名和分析开放语言学习模型(llm)和聊天机器人。这个新颖的平台大大简化了评估和基准测试语言模型的过程。您可以通过专用的“提交”页面方便地提交模型,以便在 gpu 集群上进行自动评估。
开放llm排行榜之所以高效,是因为它在eleuther ai语言模型评估工具上运行的坚实后端。eleuther ai的这一先进系统以其卓越的计算能力堪称典范。它可以有效地计算准确的基准数字,客观地衡量语言学习模型和聊天机器人的性能水平。
要查看最新的open llm排行榜,请跳转到拥抱脸网站。目前车库-baind/鸭嘴兽2-70b-instruct目前位于排行榜的顶部。在其他实验室中,请查看alpacaeval排行榜和mt bench以及其他重要资源,以了解当前llm模型的性能。
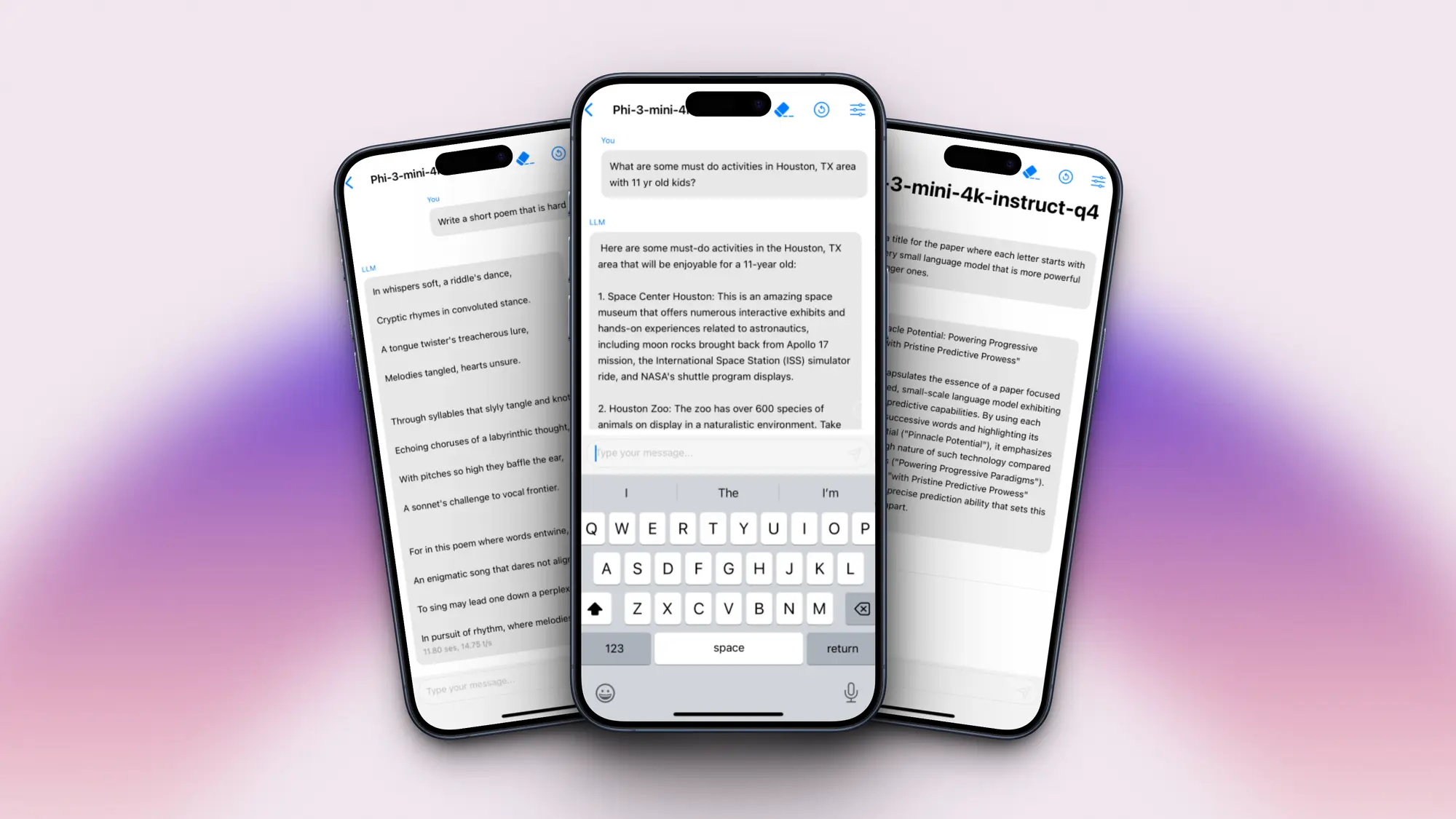
代理工作台 ai 基准测试工具演示
agentbench是一个非凡的新基准测试工具,专门用于评估语言学习模型(llm)的性能和准确性。这种以人工智能为重点的工具为技术行业带来了重大升级——该行业对更复杂的人工智能产品的需求从未如此之高。
通过提供有关llm功能能力的可量化数据,该基准测试工具使开发人员和团队能够找到潜在的改进领域,为人工智能技术的发展做出重大贡献。除了评估现有的语言模型外,该工具还有助于设计和测试新的人工智能系统。
此外,该基准测试工具旨在促进对llm的公开,透明的评估,推动ai行业朝着更大的问责制和改进方向发展。它揭开了人工智能“黑匣子”的面纱,使公众更容易理解和审查这些复杂的技术。
在这个快速发展和竞争激烈的市场中,像agentbench基准测试工具这样的凯发体育app的解决方案比以往任何时候都更加重要。它的推出标志着人工智能技术向前迈出了重要一步,有望彻底改变语言学习模型在众多领域的开发和应用,从虚拟辅助到数据分析、科学研究等。
基准测试工具的评估过程是彻底和多方面的。它评估模型对用户输入的理解、对上下文的感知、检索信息的能力以及语言的流畅性和连贯性。这种全面的方法可确保该工具提供模型功能的整体视图。
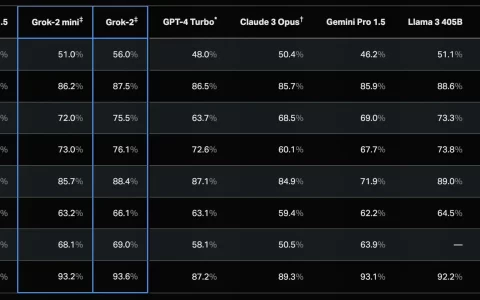
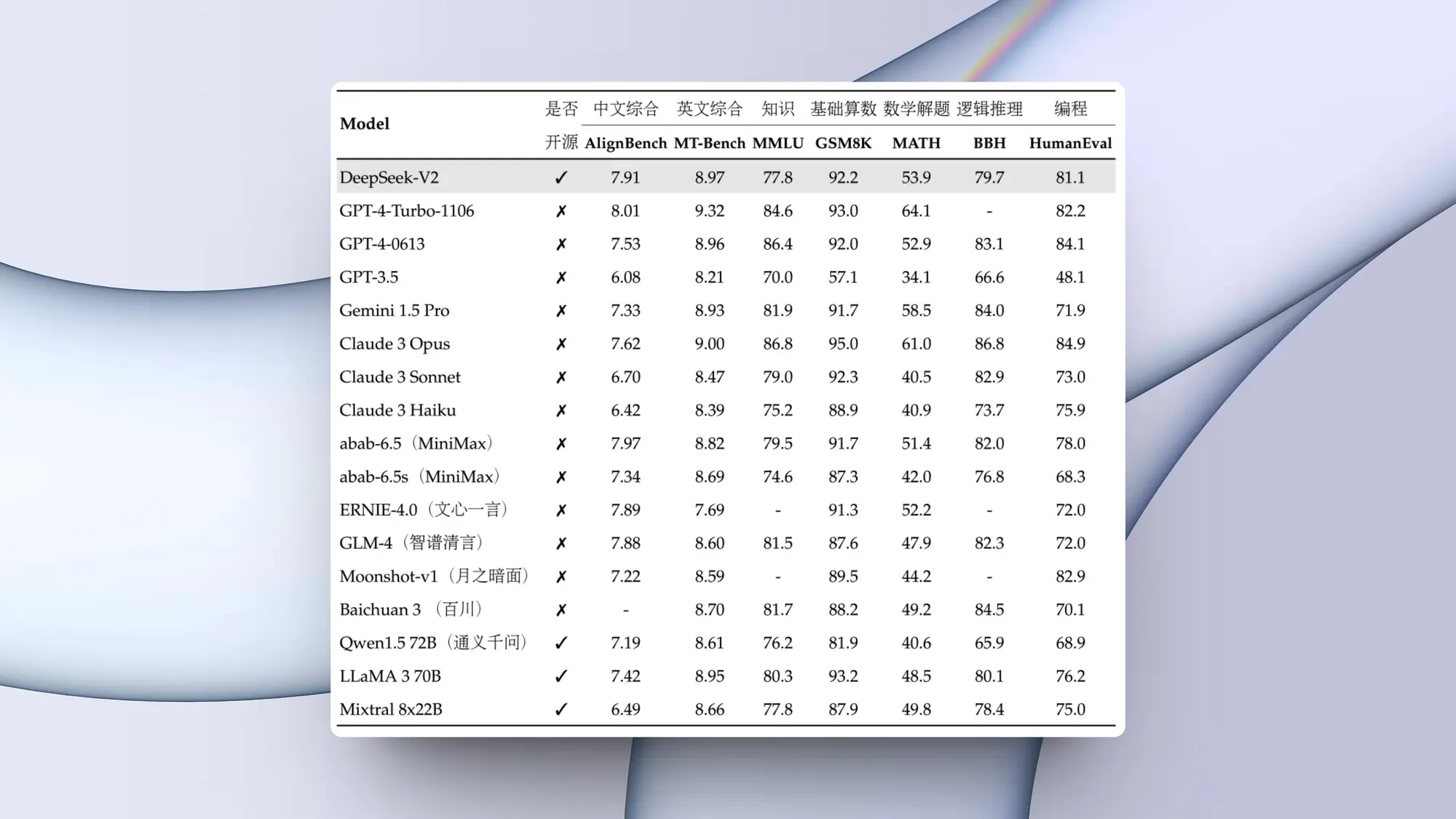
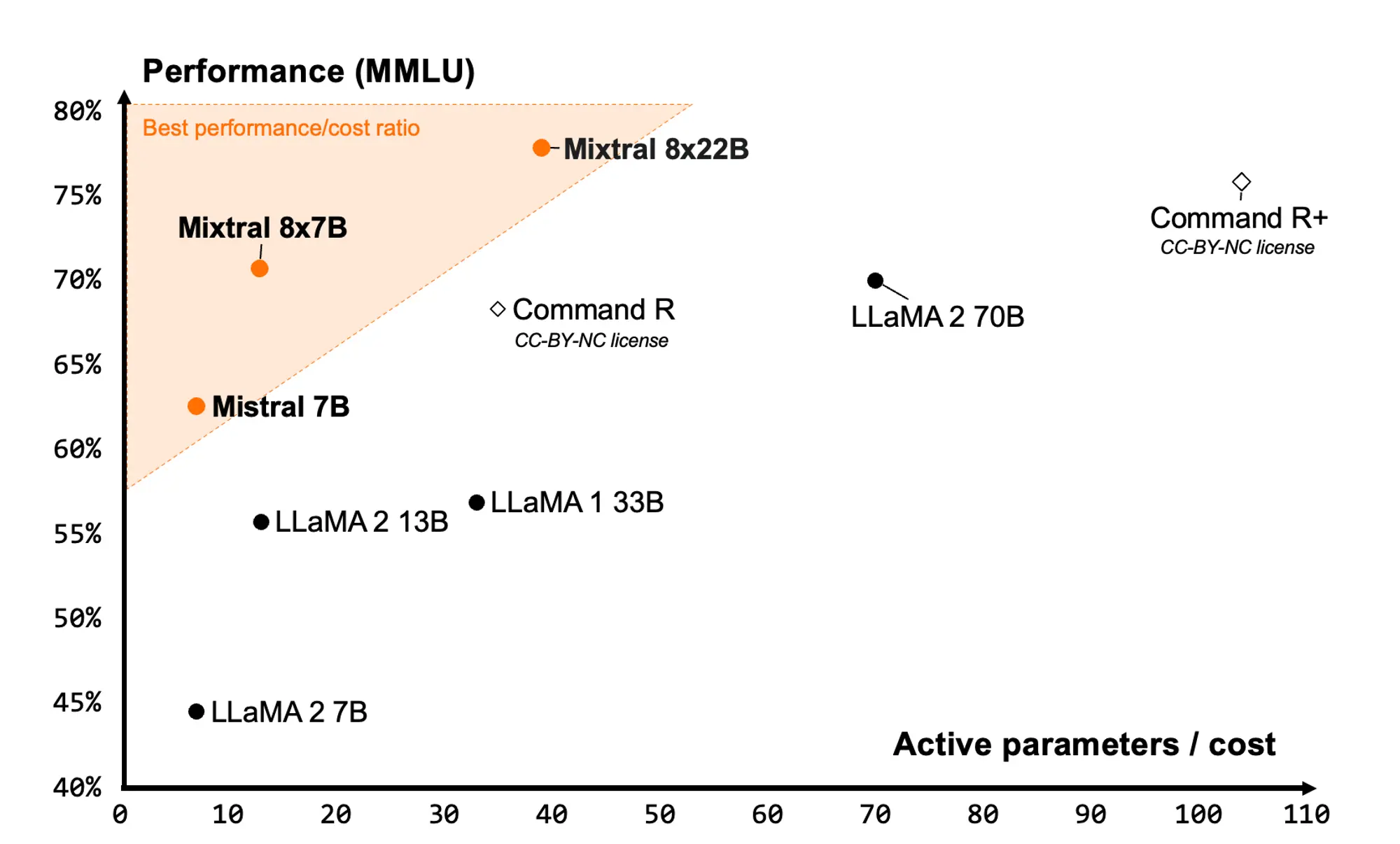
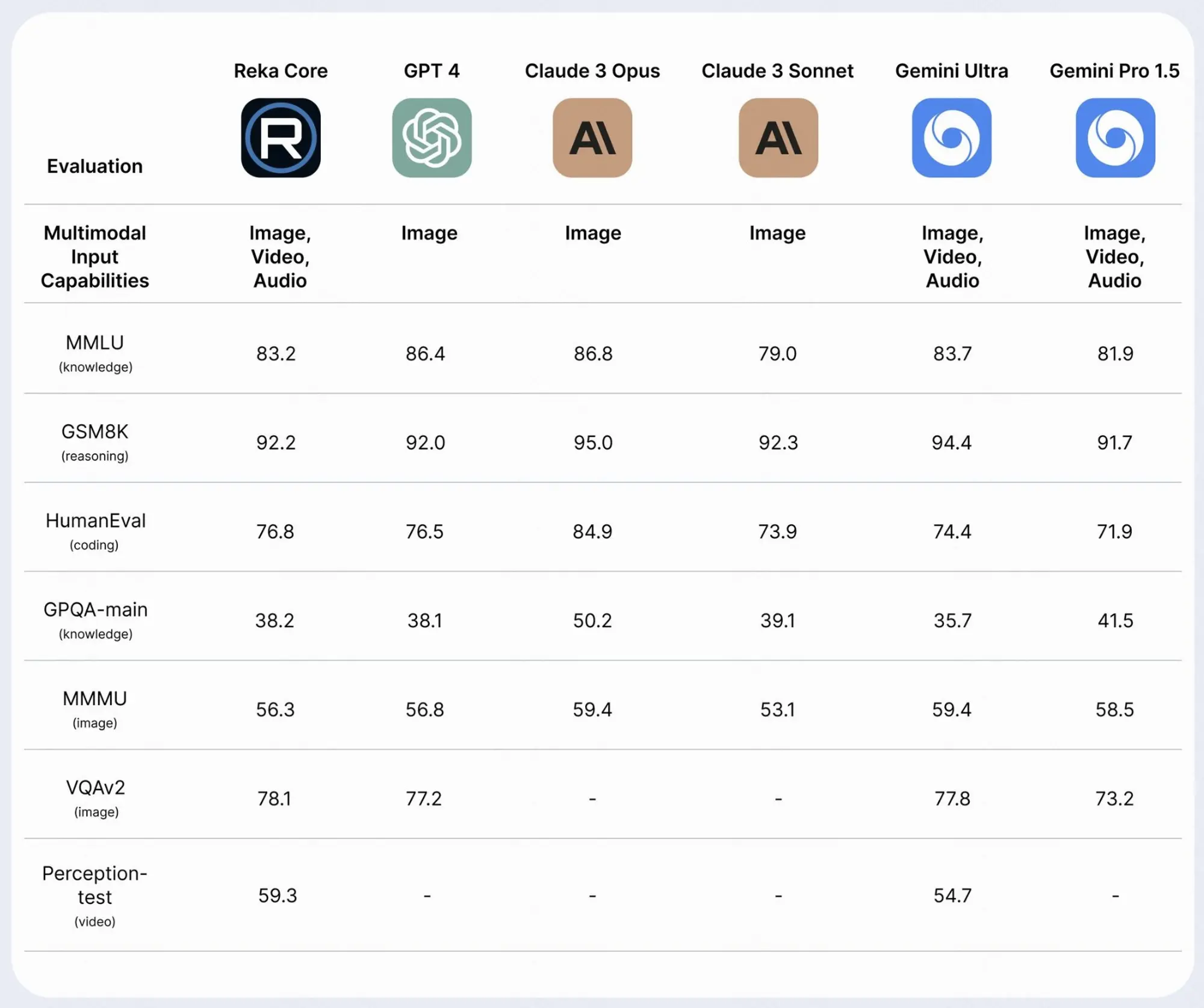
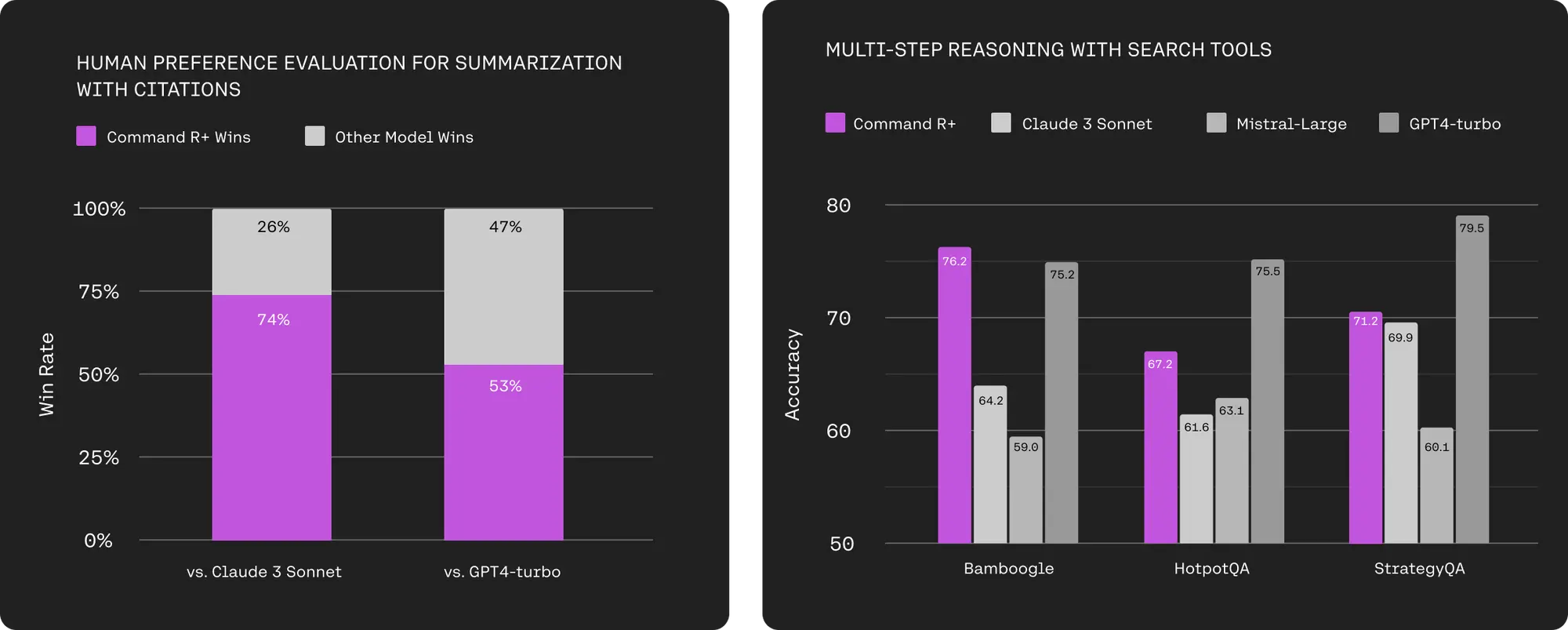
agent bench已经进行了测试,评估了25种不同的大型语言模型。其中包括来自openai等知名ai组织的模型,anthropic的claude模型和google模型。结果很有启发性,突出了大型语言模型作为代理的熟练程度,并揭示了不同模型之间的显着性能差距。
要使用代理工作台,用户需要一些关键工具。其中包括api密钥,python,作为代码编辑器的visual studio code,以及用于将存储库克隆到桌面上的git。一旦这些就位,该工具可用于评估模型在各种环境中的性能。这些范围从操作系统和数字纸牌游戏到数据库、家务、网络购物和网页浏览。
评估大型语言模型
agent bench是一个突破性的工具,旨在彻底改变大型语言模型的评估方式。其全面、多环境的评估流程和开源性质使其成为人工智能行业的宝贵资产。随着它继续对更多模型进行排名和评估,它无疑将为大型语言模型作为代理的能力和潜力提供宝贵的见解。
agentbench基准测试工具不仅仅是一项先进技术;对于世界各地从事人工智能开发的个人和组织来说,它是必不可少的资产。公司和研究人员可以使用此工具比较各种语言学习模型的优势和劣势。因此,它们可以显着加快开发周期,降低成本,构建更先进的系统,并最终创建更好的ai产品。
agentbench基准测试工具是一项令人兴奋的,改变游戏规则的技术创新。它将改变人工智能开发人员设计、开发和增强语言学习模型的方式,推动人工智能行业的进步并建立新标准。
法学硕士基准测试
无论您是开发了创新的语言学习模型还是复杂的聊天机器人,您都可以以无与伦比的精度对其进行评估。gpu集群的使用进一步提高了评估过程的可行性和速度。
open llm 排行榜通过为开发人员提供评估其模型在各种测试中性能的途径,使 ai 技术民主化。它与eleuther ai语言模型评估工具的合作保证了对通常复杂到分级的技术进行严格和公正的评估。
开放llm排行榜的独特产品通过对开放式llm和聊天机器人进行更快和与部门无关的评估,为人工智能技术开辟了新的前景。对于开发团队来说,这可能意味着及时的反馈、更快的迭代、改进的模型,并最终为日常生活中的人工智能做出更好的贡献。
llm排行榜代表了人工智能技术和软件行业错综复杂的部分,提供了新的基准和全面的评估数据点。通过对其强大后端的不懈承诺,开发人员可以期望产生有价值的见解并提高其语言模型和聊天机器人的性能。
原创文章,作者:校长,如若转载,请注明出处:https://www.yundongfang.com/yun249480.html
 微信扫一扫不于多少!
微信扫一扫不于多少!  支付宝扫一扫礼轻情意重
支付宝扫一扫礼轻情意重